ParkML
Machine learning powered parking sign reader for driverless cars.
This project is a future program that could be integrated directly into driverless vehicles. With just a camera, the car could take a picture of the area in front of it to find a parking spot that it could take.
However, this was inspired by a more current problem in my life. Whenever I parked, I would spend more time than I should've to parse the confusing language on the sign to decide whether or not I could park there. The text was small and weirdly ordered, and there were often multiple signs to consider at a spot.
This system can determine whether they can park in the current spot and for how long.
Pipeline design choices
There are three main actions that this algorithm takes to parse the sign:
- Object detection: Locate the sign in an image and crop it
- OCR: Parse the text from the sign
- Rule classifier: Using the text, figure out the parking restrictions

Object detection
Given a camera image from a driverless car, the algorithm would need to detect the sign it needs to read. Object detection can do this.
I decided to train my model on top of YOLOv8, an existing model that is incredible at object detection. With just a little training, YOLOv8 can learn and recognize a new object with astonishing accuracy. The best way I've seen this described is like teaching a human to identify a new object once it already has the concept of an object (i.e., "A is for Apple, this is an Apple").
YOLOv8 can detect many objects, but not parking signs, so we must train it.
Training
I found this dataset of San Francisco street signs on Kaggle.
The dataset quality wasn't the best- images came from Google Street View and weren't the best quality. If I re-did this step, I would clean many of these low-quality sign images to increase the detection accuracy.


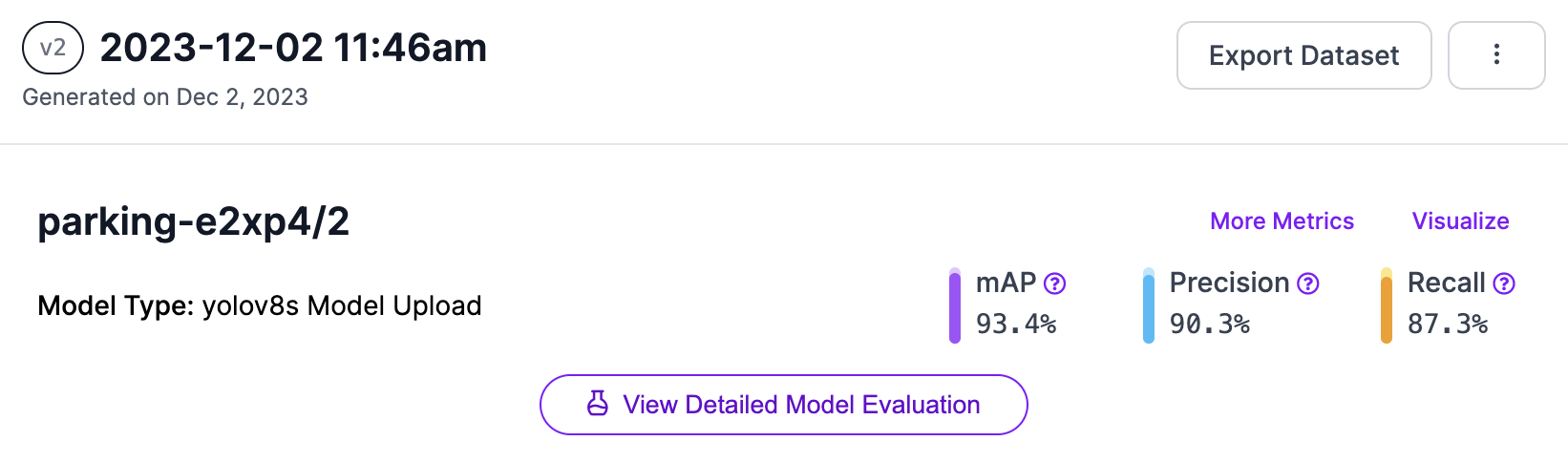
I split the data into test, training, and validation, then trained the model on Google Colab with 25 epochs.
It resulted in a 90.3% precision, 93.4% mAP, and 87.3% recall. Not bad at all, right?
Cropping
I wrote a script that prompted a user for a file, ran it through object detection above, and cropped the image to the sign's size. I tested it with a few signs from around the neighborhood at different times and was super satisfied with the result.

OCR text detection
To parse the words from the cropped sign image, I used the KerasOCR package. It was one of the first packages I found, though, and I am sure there are better options. It made a lot of mistakes.


Restriction classifier
The final step was to convert this OCR text into actual parking rules. There were multiple ways to do this, but I opted to use an explicitly defined algorithm based on the design of San Francisco's parking signs to decode the actual times.
This was challenging, as text labels on their own had no order. This code uses ratios in the sizes of the always displayed "Parking" label to find positions of other aspects of the sign.
Unfortunately, the OCR made many small mistakes with the signs. One idea was to pipe all the labels into ChatGPT to parse or at least correct OCR mistakes, which is an interesting idea for later!
Eventually, with a corrected OCR, the program might input the current time to see if you can park at the current moment. This is more of a proof of concept!
The output of the script? The times you're able to park in the spot.

Going forward
I learned a ton about ML pipelines and how to build each specific node at a low level. I'd love to expand this to work directly on a car, potentially integrating with Tesla cameras. That would require having a Tesla, though.
The pipeline I created for this project can be found on Google Colab here. Feel free to contact me with questions!

